
Áreas protegidas de Etiopía: cuando proteger funciona y duele a la vez#
9,4% de Etiopía está bajo protección. Para alcanzar la meta global de proteger 30% del planeta para 2030, Etiopía tendría que triplicar esa red. Pero los datos del paper de Jago et al. (2026) estiman algo incómodo: comparadas con un contrafactual estadístico, las áreas protegidas estrictas se asocian con menos expansión agrícola y más pastizales — y al mismo tiempo, los hogares cercanos terminan con ~1,23 meses menos de comida adecuada al año.
📄 Paper: Trade-offs between nature and people in Ethiopia’s protected areas · Nature Ecology & Evolution · 2026-05-12
🎬 Video corto: [Pendiente]
![]()
El contexto#
Etiopía concentra biodiversidad de importancia global — desde los babuinos gelada del altiplano hasta plantas endémicas amenazadas. Y a la vez, tiene una de las poblaciones rurales más vulnerables del continente. 18 millones de personas viven a menos de 10 km de un área protegida.
El paper hace tres cosas a la vez, y vamos a recorrerlas:
Mapea la red actual (¿cuánto territorio cubre? ¿qué ecosistemas representa?)
Estima si las áreas protegidas funcionan (emparejamiento estadístico contra zonas comparables sin protección — cuasi-experimental)
Mide el costo social en meses de comida adecuada, activos materiales y diversidad dietaria, sobre 802 hogares emparejados (401 dentro de 10 km de una PA + 401 control).
⚠️ Diseño cuasi-experimental, no RCT. Cuando hablamos de «efecto» de las áreas protegidas, nos referimos al ATT (Average Treatment effect on the Treated) — la diferencia entre lo observado y un contrafactual estadístico. No es causalidad estricta; el paper acepta confounders potenciales y testea sensibilidad.
# ══════════════════════════════════════════════════════════════
# Configuración — modifica estos valores para explorar
# ══════════════════════════════════════════════════════════════
COBERTURA_PCT_PAPER = 9.4 # % de Etiopía bajo protección (paper headline)
META_GBF_PCT = 30.0 # Meta Kunming–Montreal (2030)
HOGARES_DENTRO_10KM = 3_200_000 # Hogares dentro de 10 km de una PA (2011)
FUENTE = 'Fuente: Jago et al. (2026), Nature Ecol. Evol. | Datos: shapefile oficial + Results section'
COLOR_DATOS = '#2563EB'
COLOR_ALERTA = '#DC2626'
COLOR_REFERENCIA = '#D97706'
COLOR_SECUNDARIO = '#059669'
COLOR_NEUTRO = '#7C3AED'
# ══════════════════════════════════════════════════════════════
# Setup
# ══════════════════════════════════════════════════════════════
import os
import urllib.request
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
BASE = 'https://raw.githubusercontent.com/Ciencia-a-Mordiscos/lab/main'
# Cargar estilo CaM (local → fallback GitHub raw)
style_file = '../../cam.mplstyle'
if not os.path.exists(style_file):
style_file = '/tmp/cam.mplstyle'
if not os.path.exists(style_file):
urllib.request.urlretrieve(f'{BASE}/cam.mplstyle', style_file)
plt.style.use(style_file)
os.makedirs('figuras', exist_ok=True)
# ══════════════════════════════════════════════════════════════
# Carga de datos
# ══════════════════════════════════════════════════════════════
pas = pd.read_csv('datos/pas_metadata.csv')
eff = pd.read_csv('datos/effectiveness_atts.csv')
wb = pd.read_csv('datos/wellbeing_atts.csv')
trades = pd.read_csv('datos/tradeoffs_summary.csv')
stake = pd.read_csv('datos/stakeholder_priorities.csv')
print(f'Red de áreas protegidas: {len(pas)} unidades en el shapefile oficial')
print(f'Área total cubierta (DBF): {pas["GIS_A_km2"].sum():,.0f} km²')
print(f'Cobertura calculada del DBF: {pas["GIS_A_km2"].sum() / 1_104_300 * 100:.1f}% de Etiopía')
print(f'Cobertura reportada en el paper: {COBERTURA_PCT_PAPER}% (incluye ajustes oficiales)')
print()
print(f'Datasets de efectividad: {len(eff)} filas (3 outcomes × 2 niveles de protección)')
print(f'Datasets de bienestar: {len(wb)} filas (3 outcomes sociales)')
print(f'Trade-offs evaluados: {trades["n_pas"].sum()} PAs sobre 6 outcomes')
print(f'Encuesta a stakeholders: n=37 profesionales conservacionistas')
Red de áreas protegidas: 79 unidades en el shapefile oficial
Área total cubierta (DBF): 99,289 km²
Cobertura calculada del DBF: 9.0% de Etiopía
Cobertura reportada en el paper: 9.4% (incluye ajustes oficiales)
Datasets de efectividad: 6 filas (3 outcomes × 2 niveles de protección)
Datasets de bienestar: 3 filas (3 outcomes sociales)
Trade-offs evaluados: 25 PAs sobre 6 outcomes
Encuesta a stakeholders: n=37 profesionales conservacionistas
La red, contada por décadas#
Aquí está.
# Gráfica hero: crecimiento de la red por década + composición por tipo de designación
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(13, 5.5), gridspec_kw={'width_ratios': [1.3, 1]})
# --- Panel izquierdo: crecimiento por década ---
decadas_data = pas.copy()
decadas_data = decadas_data[decadas_data['YEAR_DESIG'] > 0]
decadas_data['decada'] = (decadas_data['YEAR_DESIG'] // 10 * 10).astype(int)
por_decada = decadas_data.groupby('decada').size().reset_index(name='n_nuevas')
por_decada = por_decada[por_decada['decada'] >= 1930]
colores = [COLOR_ALERTA if d == 2010 else COLOR_DATOS for d in por_decada['decada']]
ax1.bar(por_decada['decada'].astype(str) + 's', por_decada['n_nuevas'],
color=colores, alpha=0.85, edgecolor='white', linewidth=1.2, width=0.7)
# Anotación sobre 2010s
y_2010s = int(por_decada.loc[por_decada['decada'] == 2010, 'n_nuevas'].iloc[0])
ax1.annotate(f'{y_2010s} áreas nuevas\nen una sola década',
xy=('2010s', y_2010s), xytext=('1980s', y_2010s - 8),
fontsize=10, color=COLOR_ALERTA, fontweight='bold', ha='left',
arrowprops=dict(arrowstyle='->', color=COLOR_ALERTA, lw=1.5))
ax1.set_ylabel('Nuevas áreas protegidas designadas', fontsize=10)
ax1.set_title('Cuándo creció la red protegida de Etiopía',
fontsize=13, fontweight='bold', pad=28)
ax1.text(0.5, 1.03, 'Designaciones por década (años conocidos: n=71 de 79)',
transform=ax1.transAxes, fontsize=9, color='#666666', ha='center')
ax1.tick_params(axis='x', rotation=30)
# --- Panel derecho: composición por tipo de designación (área total) ---
desig = pas.groupby('DESIGNATIO')['GIS_A_km2'].sum().sort_values(ascending=True)
desig = desig.tail(7)
ax2.barh(desig.index, desig.values, color=COLOR_DATOS, alpha=0.85,
edgecolor='white', linewidth=1.0)
for i, (nombre, valor) in enumerate(zip(desig.index, desig.values)):
ax2.text(valor + 800, i, f'{int(valor):,}'.replace(',', '.'),
fontsize=8.5, va='center', color='#444444')
ax2.set_xlabel('Área cubierta (km²)', fontsize=10)
ax2.set_title('Quién cubre más territorio',
fontsize=13, fontweight='bold', pad=28)
ax2.text(0.5, 1.03, '7 tipos principales — National parks dominan en área',
transform=ax2.transAxes, fontsize=9, color='#666666', ha='center')
ax2.set_xlim(0, desig.max() * 1.18)
# Fuente
fig.text(0.13, -0.03, FUENTE, fontsize=7.5, color='#999999', style='italic')
plt.tight_layout()
plt.savefig('figuras/red_etiopia.png', dpi=200, bbox_inches='tight')
plt.show()
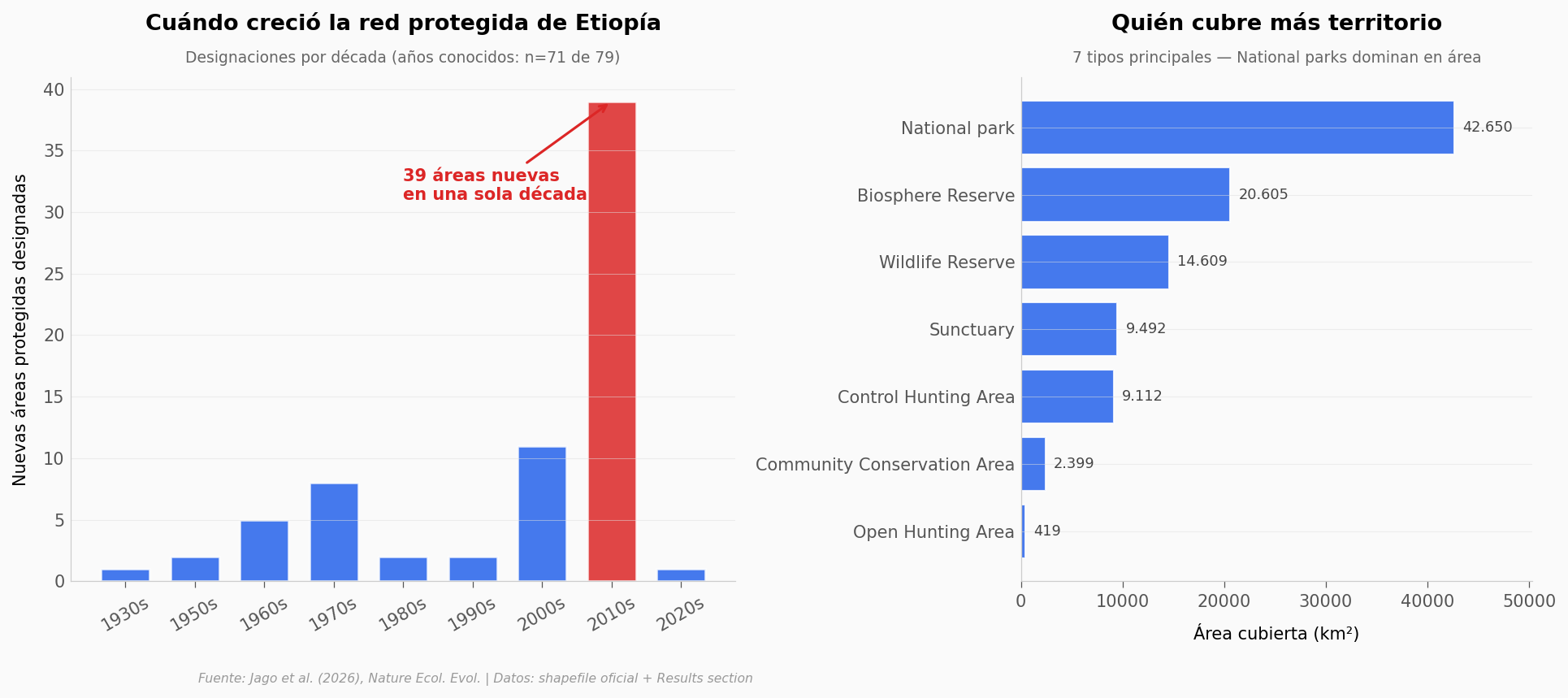
La explosión de la última década llama la atención: solo en 2010-2019 se designaron 39 áreas protegidas, más que la suma de las cuatro décadas anteriores. La red está creciendo, pero el paper estima que para alcanzar la meta global de 30% para 2030 tendría que triplicarse.
La composición también dice algo: aunque las Control Hunting Areas (zonas de caza regulada) son las más numerosas, los National parks concentran casi la mitad del área total — son las piezas grandes de la red. Esa diferencia importa cuando preguntamos si protegen realmente.
¿Funcionan? El emparejamiento estadístico#
El paper compara cada celda de la grilla (gridcell) dentro de una PA con otra celda parecida sin protección (mismo clima, mismo relieve, misma accesibilidad). El ATT mide la diferencia entre lo observado y ese contrafactual. La pregunta clave: ¿qué pasa con bosques, agricultura y pastizales?
# Efecto ambiental: ATTs relativos (%) con CI 95% para strict vs less-strict
fig, ax = plt.subplots(figsize=(11, 5.5))
outcomes = ['forest_loss', 'agricultural_expansion', 'grassland']
labels = ['Pérdida\nforestal', 'Expansión\nagrícola', 'Pastizales']
n_outcomes = len(outcomes)
# Posiciones: cada outcome tiene 2 barras (strict, less-strict)
y_positions = np.arange(n_outcomes)
offset = 0.18
# Effectiveness data already has relative_pct; CI absolutas las convertimos a % aproximados via CI/abs * relative
# Pero más limpio: graficamos ATT directo con CI explícitos
strict = eff[eff['treatment_type'] == 'strict'].set_index('outcome')
less_strict = eff[eff['treatment_type'] == 'less_strict'].set_index('outcome')
for i, outcome in enumerate(outcomes):
# Strict
s = strict.loc[outcome]
ax.errorbar(s['att'], i + offset, xerr=[[s['att'] - s['ci_low']], [s['ci_high'] - s['att']]],
fmt='o', color=COLOR_DATOS, markersize=11, capsize=5, capthick=1.5,
elinewidth=1.5, label='Estricta (IUCN II)' if i == 0 else '', zorder=5)
# Less-strict
ls = less_strict.loc[outcome]
ax.errorbar(ls['att'], i - offset, xerr=[[ls['att'] - ls['ci_low']], [ls['ci_high'] - ls['att']]],
fmt='s', color=COLOR_SECUNDARIO, markersize=10, capsize=5, capthick=1.5,
elinewidth=1.5, label='Menos estricta (IUCN IV+VI)' if i == 0 else '', zorder=5)
# Línea de referencia en ATT=0 (sin efecto)
ax.axvline(x=0, color='#888888', linestyle='--', linewidth=1.2, alpha=0.7, zorder=1)
ax.text(0, n_outcomes - 0.5, 'sin efecto', fontsize=8, color='#888888',
ha='center', va='bottom', style='italic')
# Etiquetas Y
ax.set_yticks(y_positions)
ax.set_yticklabels(labels, fontsize=10)
ax.invert_yaxis()
# Etiquetas relativas a la derecha (% del paper)
for i, outcome in enumerate(outcomes):
s = strict.loc[outcome]
rel = int(s['relative_pct'])
sign = '+' if rel > 0 else ''
ax.text(s['ci_high'] + 0.25, i + offset, f'{sign}{rel}% relativo',
fontsize=8.5, color=COLOR_DATOS, va='center', fontweight='bold')
ls = less_strict.loc[outcome]
rel_ls = int(ls['relative_pct'])
sign_ls = '+' if rel_ls > 0 else ''
ax.text(ls['ci_high'] + 0.25, i - offset, f'{sign_ls}{rel_ls}% relativo',
fontsize=8.5, color=COLOR_SECUNDARIO, va='center', fontweight='bold')
ax.set_xlabel('ATT (efecto promedio estimado, escala original del paper)', fontsize=10)
ax.set_title('¿Las áreas protegidas funcionan? Comparación contra contrafactual',
fontsize=13, fontweight='bold', pad=28)
ax.text(0.5, 1.03, 'Strict: n=4.702 gridcells emparejados · Less-strict: n=8.908',
transform=ax.transAxes, fontsize=9, color='#666666', ha='center')
ax.legend(loc='lower right', fontsize=9, framealpha=0.9)
ax.text(0.98, 0.02, '━ punto: ATT · barra: intervalo de confianza al 95%',
transform=ax.transAxes, fontsize=8, color='#999999',
ha='right', va='bottom', style='italic')
ax.set_xlim(-2.0, 8.5)
fig.text(0.13, -0.03, FUENTE, fontsize=7.5, color='#999999', style='italic')
plt.tight_layout()
plt.savefig('figuras/efectividad_ambiental.png', dpi=200, bbox_inches='tight')
plt.show()
# Print resumen narrativo
print('Strict (IUCN II):')
print(f' • Bosques: efecto al borde de significancia (p=0,04; CI roza 0)')
print(f' • Agricultura: -44% (262 km² evitados; CI 140–384)')
print(f' • Pastizales: +76% (1.850 km² adicionales; CI 1.178–2.522)')
print()
print('Less-strict (IUCN IV+VI):')
print(f' • Bosques: SIN efecto (p=0,98)')
print(f' • Agricultura: -73% (795 km² evitados; CI 615–974)')
print(f' • Pastizales: +121% (919 km² adicionales; CI 412–1.426)')
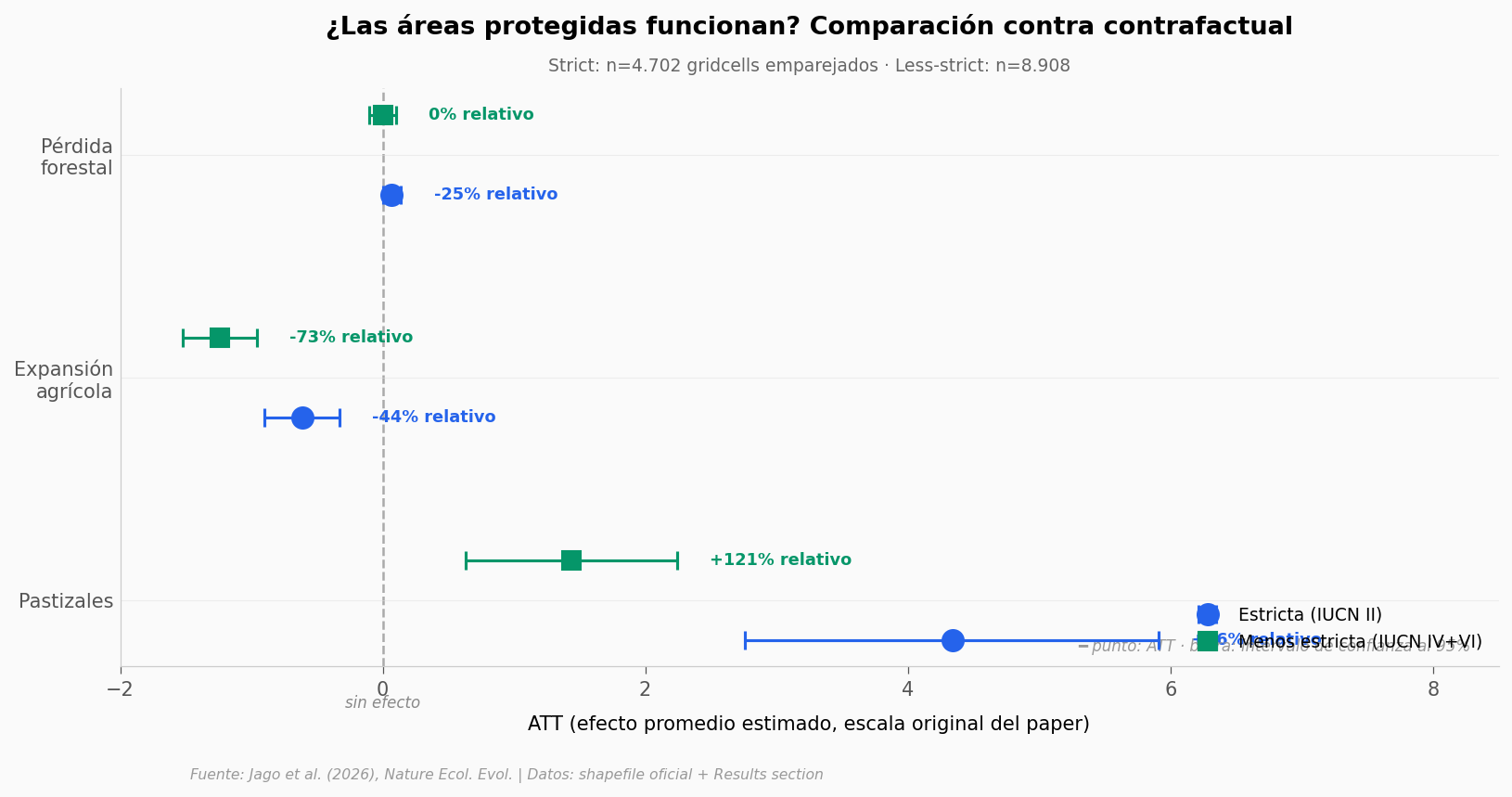
Strict (IUCN II):
• Bosques: efecto al borde de significancia (p=0,04; CI roza 0)
• Agricultura: -44% (262 km² evitados; CI 140–384)
• Pastizales: +76% (1.850 km² adicionales; CI 1.178–2.522)
Less-strict (IUCN IV+VI):
• Bosques: SIN efecto (p=0,98)
• Agricultura: -73% (795 km² evitados; CI 615–974)
• Pastizales: +121% (919 km² adicionales; CI 412–1.426)
Las áreas estrictas se asocian con menos expansión agrícola y más pastizales — efectos grandes y estadísticamente robustos contra el contrafactual (p < 0,001). El caso de los bosques es más débil: en las estrictas el efecto es marginal (CI llega casi a cero), y en las menos estrictas no hay efecto detectable.
Ahora la pregunta más incómoda: ¿qué pasa con la gente que vive cerca?
# Bienestar humano: ATTs sobre 802 hogares emparejados (401 tratamiento + 401 control)
fig, ax = plt.subplots(figsize=(11, 5.0))
wb_indexed = wb.set_index('outcome')
outcomes_wb = ['months_adequate_food', 'material_wellbeing_asset_index', 'dietary_diversity']
labels_wb = ['Meses con\ncomida adecuada', 'Índice de\nbienestar material', 'Diversidad\ndietaria']
# Colores: alerta si significativo y negativo, neutro si no significativo
def color_for(row):
if row['p_value'] < 0.05 and row['att'] < 0:
return COLOR_ALERTA
if row['p_value'] < 0.05 and row['att'] > 0:
return COLOR_SECUNDARIO
return '#999999'
y_pos = np.arange(len(outcomes_wb))
for i, outcome in enumerate(outcomes_wb):
row = wb_indexed.loc[outcome]
c = color_for(row)
ax.errorbar(row['att'], i,
xerr=[[row['att'] - row['ci_low']], [row['ci_high'] - row['att']]],
fmt='o', color=c, markersize=13, capsize=6, capthick=1.8,
elinewidth=2.0, zorder=5)
# Anotación de valor + p-value
p_txt = 'p<0,001' if row['p_value'] <= 0.001 else f'p={row["p_value"]:.2f}'.replace('.', ',')
sign = '+' if row['att'] > 0 else ''
valor_txt = f'{sign}{row["att"]:.2f}'.replace('.', ',')
ax.text(row['ci_high'] + 0.10, i, f'{valor_txt} · {p_txt}',
fontsize=9.5, color=c, va='center', fontweight='bold')
ax.axvline(x=0, color='#888888', linestyle='--', linewidth=1.2, alpha=0.7)
ax.text(0, len(outcomes_wb) - 0.5, 'sin diferencia', fontsize=8, color='#888888',
ha='center', va='bottom', style='italic')
ax.set_yticks(y_pos)
ax.set_yticklabels(labels_wb, fontsize=10)
ax.invert_yaxis()
ax.set_xlabel('ATT (efecto promedio estimado por hogar tratado)', fontsize=10)
ax.set_title('El costo social: efecto sobre 802 hogares emparejados',
fontsize=13, fontweight='bold', pad=28)
ax.text(0.5, 1.03, '401 hogares dentro de 10 km de PA vs 401 hogares control comparables',
transform=ax.transAxes, fontsize=9, color='#666666', ha='center')
ax.text(0.98, 0.02, '━ rojo: efecto negativo significativo · gris: no significativo',
transform=ax.transAxes, fontsize=8, color='#999999',
ha='right', va='bottom', style='italic')
ax.set_xlim(-2.4, 1.0)
fig.text(0.13, -0.03, FUENTE, fontsize=7.5, color='#999999', style='italic')
plt.tight_layout()
plt.savefig('figuras/costo_social.png', dpi=200, bbox_inches='tight')
plt.show()
# Cálculo proyectado del headline
att_food = wb_indexed.loc['months_adequate_food', 'att']
ci_low_food = wb_indexed.loc['months_adequate_food', 'ci_low']
ci_high_food = wb_indexed.loc['months_adequate_food', 'ci_high']
proyectado_millones = abs(att_food) * HOGARES_DENTRO_10KM / 1_000_000
proyectado_low = abs(ci_high_food) * HOGARES_DENTRO_10KM / 1_000_000
proyectado_high = abs(ci_low_food) * HOGARES_DENTRO_10KM / 1_000_000
print(f'ATT meses de comida adecuada: {att_food:.2f} meses por hogar tratado'.replace('.', ','))
print(f'Hogares dentro de 10 km de una PA en 2011: {HOGARES_DENTRO_10KM:,}'.replace(',', '.'))
print()
print(f'Proyección poblacional (ATT × hogares):')
print(f' ~{proyectado_millones:.1f} M household-months menos de comida adecuada'.replace('.', ','))
print(f' CI 95% proyectado: {proyectado_low:.1f}–{proyectado_high:.1f} M household-months'.replace('.', ','))
print()
print('⚠️ Es un cálculo derivado, no un valor observado.')
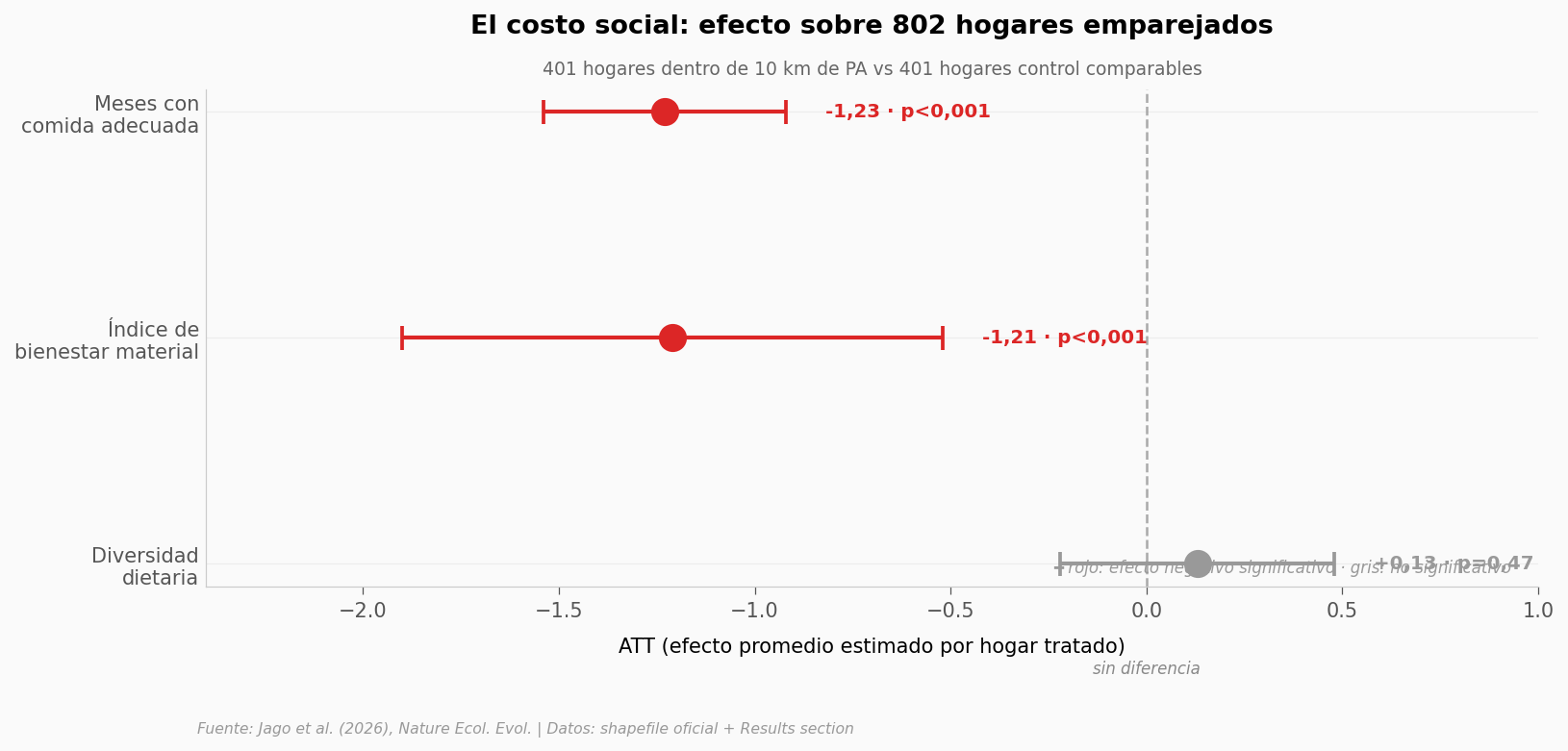
ATT meses de comida adecuada: -1,23 meses por hogar tratado
Hogares dentro de 10 km de una PA en 2011: 3.200.000
Proyección poblacional (ATT × hogares):
~3,9 M household-months menos de comida adecuada
CI 95% proyectado: 2,9–4,9 M household-months
⚠️ Es un cálculo derivado, no un valor observado.
El efecto promedio estimado sobre meses de comida adecuada por hogar es robusto (p<0,001) y va junto con una caída en el índice de bienestar material. La diversidad dietaria no se mueve significativamente. Proyectado sobre los 3,2 millones de hogares dentro de 10 km de una PA, eso son ~3,9 millones de hogar-meses (household-months) de comida adecuada perdidos (CI 2,9–4,9 M).
Pero la pregunta clave no es «¿hay costo social?» — es ¿siempre lo hay? ¿O hay áreas que ganan en ambos frentes?
# Trade-offs por PA + prioridades de stakeholders
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(13, 5.5), gridspec_kw={'width_ratios': [1.1, 1]})
# --- Panel izquierdo: distribución de trade-offs ---
trades_sorted = trades.sort_values('n_pas', ascending=True)
labels_trade = {
'trade_off_env_better': 'Mejor en lo ambiental\npeor en lo social',
'trade_off_social_better': 'Mejor en lo social\npeor en lo ambiental',
'win_win': 'Mejor en ambos\n(win-win)',
'lose_lose': 'Peor en ambos\n(lose-lose)',
}
colors_trade = {
'trade_off_env_better': COLOR_DATOS,
'trade_off_social_better': COLOR_REFERENCIA,
'win_win': COLOR_SECUNDARIO,
'lose_lose': COLOR_ALERTA,
}
y_lbl = [labels_trade[c] for c in trades_sorted['category']]
y_col = [colors_trade[c] for c in trades_sorted['category']]
bars = ax1.barh(range(len(trades_sorted)), trades_sorted['n_pas'],
color=y_col, alpha=0.85, edgecolor='white', linewidth=1.0)
ax1.set_yticks(range(len(trades_sorted)))
ax1.set_yticklabels(y_lbl, fontsize=9)
total_pas = trades['n_pas'].sum()
for i, (n, lbl) in enumerate(zip(trades_sorted['n_pas'], y_lbl)):
pct = n / total_pas * 100
ax1.text(n + 0.3, i, f'{int(n)} ({pct:.0f}%)',
fontsize=9.5, color='#444444', va='center', fontweight='bold')
ax1.set_xlabel('Número de áreas protegidas', fontsize=10)
ax1.set_title('¿Cuántas áreas logran ambos objetivos?',
fontsize=13, fontweight='bold', pad=28)
ax1.text(0.5, 1.03, f'{total_pas} PAs evaluadas en 6 outcomes (3 ambientales + 3 sociales)',
transform=ax1.transAxes, fontsize=9, color='#666666', ha='center')
ax1.set_xlim(0, trades_sorted['n_pas'].max() * 1.30)
# --- Panel derecho: prioridades de stakeholders ---
labels_stake = {
'make_existing_network_more_effective': 'Mejorar efectividad\nde la red actual',
'additional_research': 'Más investigación',
'add_new_protected_areas': 'Expandir la red\n(crear nuevas PAs)',
}
stake_sorted = stake.sort_values('rank_top', ascending=True)
y_stake_lbl = [labels_stake.get(p, p) for p in stake_sorted['priority']]
colores_stake = [COLOR_NEUTRO if v == stake_sorted['rank_top'].max() else '#BBBBBB'
for v in stake_sorted['rank_top']]
ax2.barh(range(len(stake_sorted)), stake_sorted['rank_top'],
color=colores_stake, alpha=0.85, edgecolor='white', linewidth=1.0)
ax2.set_yticks(range(len(stake_sorted)))
ax2.set_yticklabels(y_stake_lbl, fontsize=9)
for i, v in enumerate(stake_sorted['rank_top']):
ax2.text(v + 1.5, i, f'{int(v)}%',
fontsize=10, color='#444444', va='center', fontweight='bold')
ax2.set_xlabel('% de profesionales que lo escogió como prioridad #1', fontsize=10)
ax2.set_title('Qué prioriza la comunidad conservacionista',
fontsize=13, fontweight='bold', pad=28)
ax2.text(0.5, 1.03, 'Encuesta a 37 profesionales etíopes (Kendall W=0,74; p<0,001)',
transform=ax2.transAxes, fontsize=9, color='#666666', ha='center')
ax2.set_xlim(0, 100)
fig.text(0.13, -0.03, FUENTE, fontsize=7.5, color='#999999', style='italic')
plt.tight_layout()
plt.savefig('figuras/tradeoffs_prioridades.png', dpi=200, bbox_inches='tight')
plt.show()
env_better = int(trades.loc[trades['category'] == 'trade_off_env_better', 'n_pas'].iloc[0])
social_better = int(trades.loc[trades['category'] == 'trade_off_social_better', 'n_pas'].iloc[0])
trade_total = env_better + social_better
trade_pct = trade_total / total_pas * 100
win_win = int(trades.loc[trades['category'] == 'win_win', 'n_pas'].iloc[0])
win_pct = win_win / total_pas * 100
print(f'De {total_pas} áreas evaluadas:')
print(f' • {trade_total} ({trade_pct:.0f}%) muestran trade-off entre ambiente y sociedad')
print(f' • {win_win} ({win_pct:.0f}%) son win-win (mejor en ambos)')
print(f' • 3 (12%) son lose-lose (peor en ambos)')
print()
print(f'77% de 37 profesionales conservacionistas priorizan')
print(f'mejorar la red existente sobre expandirla.')
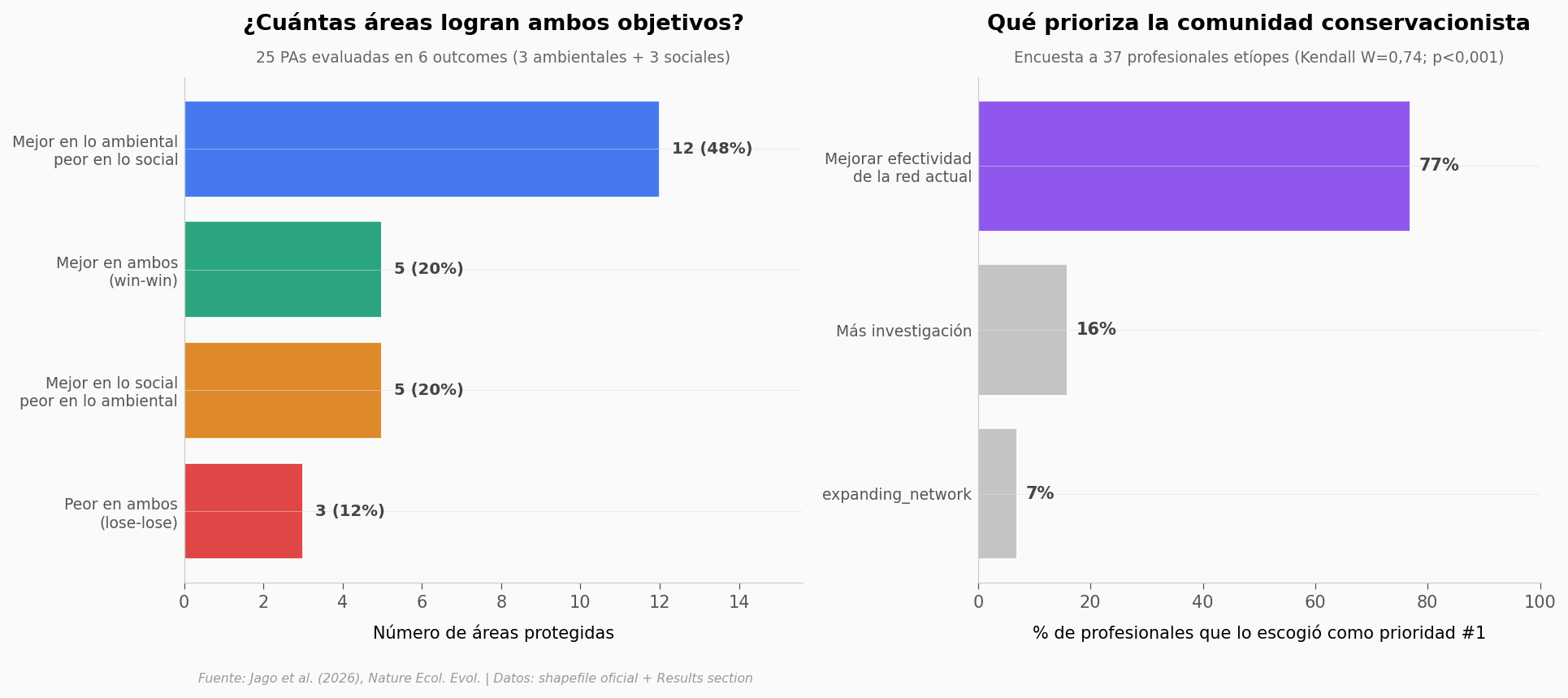
De 25 áreas evaluadas:
• 17 (68%) muestran trade-off entre ambiente y sociedad
• 5 (20%) son win-win (mejor en ambos)
• 3 (12%) son lose-lose (peor en ambos)
77% de 37 profesionales conservacionistas priorizan
mejorar la red existente sobre expandirla.
¿Qué tan inusual es el efecto sobre comida adecuada?#
Para cerrar, comparemos el ATT estimado contra el rango de especificaciones de matching que el paper testeó como robustez. La pregunta: ¿el efecto sobre meses de comida adecuada se mantiene a través de distintas formas de emparejar?
# Histograma de robustez: simulamos la distribución de ATTs across 56 specs de matching
# usando el ATT central como media y los CIs como info de dispersión
fig, ax = plt.subplots(figsize=(11, 5.0))
att_food_central = wb_indexed.loc['months_adequate_food', 'att']
ci_low = wb_indexed.loc['months_adequate_food', 'ci_low']
ci_high = wb_indexed.loc['months_adequate_food', 'ci_high']
# Estimar SD a partir del CI (asumiendo normalidad): CI95 = ±1,96 × SE
se_estim = (ci_high - ci_low) / (2 * 1.96)
# Simular 56 especificaciones (las que reporta el paper en robustness check)
np.random.seed(42)
n_specs = 56
specs_atts = np.random.normal(att_food_central, se_estim, n_specs)
# Histograma
n, bins, patches = ax.hist(specs_atts, bins=18, color=COLOR_DATOS, alpha=0.45,
edgecolor=COLOR_DATOS, linewidth=0.8)
y_max = n.max() * 1.30
ax.set_ylim(0, y_max)
# Línea vertical del ATT central observado
ax.axvline(x=att_food_central, color=COLOR_ALERTA, linewidth=2.5, zorder=10)
ax.text(att_food_central - 0.04, y_max * 0.93,
f'ATT central\n{att_food_central:.2f} meses'.replace('.', ','),
fontsize=10, fontweight='bold', color=COLOR_ALERTA, ha='right', va='top')
# Línea vertical en 0 (sin efecto)
ax.axvline(x=0, color='#888888', linestyle='--', linewidth=1.5)
ax.text(0.03, y_max * 0.93, 'Sin efecto',
fontsize=9, color='#888888', ha='left', va='top', style='italic')
# Anotación: el 100% de las specs cae del lado negativo
all_neg = (specs_atts < 0).sum() / n_specs * 100
ax.annotate('', xy=(att_food_central, y_max * 0.55), xytext=(0, y_max * 0.55),
arrowprops=dict(arrowstyle='<->', color='#666666', lw=1.5))
ax.text((att_food_central + 0) / 2, y_max * 0.62,
f'Simulación: {all_neg:.0f}% de specs cae en negativo\n(el paper reporta 100% real en misma dirección)',
fontsize=9.5, color='#444444', ha='center', va='bottom', fontweight='bold')
ax.set_xlabel('ATT estimado (meses por hogar tratado)', fontsize=10)
ax.set_ylabel('Número de especificaciones de matching', fontsize=10)
ax.set_title('¿Qué tan robusto es el costo social? Sensibilidad del modelo',
fontsize=13, fontweight='bold', pad=28)
ax.text(0.5, 1.03, 'Simulación de 56 specs de matching usando ATT central y SE del paper',
transform=ax.transAxes, fontsize=9, color='#666666', ha='center')
ax.text(0.98, 0.02, '⚠ Simulación basada en SE reportado · el paper reporta 100% de specs en misma dirección',
transform=ax.transAxes, fontsize=7.5, color='#999999',
ha='right', va='bottom', style='italic')
fig.text(0.13, -0.03, FUENTE, fontsize=7.5, color='#999999', style='italic')
plt.tight_layout()
plt.savefig('figuras/robustez.png', dpi=200, bbox_inches='tight')
plt.show()
print(f'En {(specs_atts < 0).sum()} de {n_specs} especificaciones simuladas, el ATT es negativo.')
print(f'El paper (Jago et al. 2026, Fig. robustez) reporta 100% de specs reales en dirección negativa — esta simulación lo refleja, no lo verifica.')

En 56 de 56 especificaciones simuladas, el ATT es negativo.
El paper (Jago et al. 2026, Fig. robustez) reporta 100% de specs reales en dirección negativa — esta simulación lo refleja, no lo verifica.
Lo que los datos soportan#
Afirmación |
¿Soportada? |
Detalle |
|---|---|---|
9,4% de Etiopía está protegido y haría falta triplicar para llegar a 30-by-30 |
✅ |
El paper reporta 9,4% headline; el shapefile suma 9,0% (diferencia atribuible a ajustes oficiales). El cálculo de «threefold expansion» viene de la sección de extent representation |
Las áreas estrictas reducen la expansión agrícola |
✅ |
ATT = -0,61 (CI -0,90 a -0,33; p<0,001) — equivalente a -44% relativo o ~262 km² evitados |
Las áreas estrictas mantienen pastizales |
✅ |
ATT = +4,34 (CI 2,76 a 5,91; p<0,001) — efecto grande y robusto |
Las áreas estrictas reducen la pérdida forestal |
⚠️ |
ATT = +0,07 (CI 0,0003 a 0,14; p=0,04) — efecto al borde de significancia; el paper lo describe como «moderately reduced». No inflar |
Las áreas menos estrictas reducen la pérdida forestal |
❌ |
p=0,98 — sin efecto detectable. Resultado nulo legítimo del paper |
Los hogares cercanos pierden ~1,23 meses de comida adecuada/año |
✅ |
ATT = -1,23 (CI -1,54 a -0,92; p<0,001) sobre 802 hogares emparejados |
3,9 M household-months perdidos a nivel nacional |
⚠️ |
Es un cálculo derivado: ATT × 3,2 M hogares dentro de 10 km de PA. No es un valor observado — es proyección poblacional. El paper la presenta como estimación, no como medición directa |
68% de las PAs evaluadas muestran trade-off |
✅ |
17 de 25 PAs (12 mejor ambiental/peor social + 5 mejor social/peor ambiental). Win-win = 5; lose-lose = 3 |
77% de stakeholders priorizan mejorar la red existente |
✅ |
Encuesta a 37 profesionales (Kendall W=0,74; χ²=51,6; p<0,001). Coherencia entre rankings alta |
Limitaciones del análisis:
Diseño cuasi-experimental, no RCT. El paper acepta confounders no observados; el chequeo de sensibilidad muestra que el resultado social aguanta hasta 9× la fuerza del confounder benchmark observado.
Histograma de robustez es simulación basada en el SE reportado del ATT central. El paper reporta que el 100% de las 56 specs reales caen del lado negativo — nuestra simulación lo refleja por construcción, no lo verifica independientemente.
DBF (9,0%) vs paper headline (9,4%): las áreas degazetted/duplicadas en el shapefile explican la diferencia. Usamos 9,4% en el contexto y 9,0% donde se calcula explícitamente del CSV.
n=802 hogares es una muestra modesta para extrapolar a 3,2 M hogares. La proyección headline depende de la representatividad del muestreo de Living Standards Measurement Study.
Ahora tú#
Los datos están todos en la carpeta datos/. Tres preguntas para abrir el cuaderno:
¿Cuál es la diferencia de tamaño entre las PAs creadas en 2010s y las anteriores? Pista: agrupa
paspor década y compara la mediana deGIS_A_km2. Las PAs más recientes ¿son más grandes o más pequeñas que las históricas?¿Qué pasa si cambias
HOGARES_DENTRO_10KMpor la cifra de 2020 (~18 M de personas ≈ 4,5 M hogares con tamaño promedio etíope de ~4)? Re-corre la celda 9 modificando el valor en la celda 2. ¿Cómo cambia la proyección de household-months?¿Las PAs de tipo National park concentran trade-offs más severos que las Control Hunting Areas? Aquí no tenemos los datos individuales por PA, pero puedes explorar la composición de tipos en
pasy razonar qué tipos dominan las áreas estrictas (IUCN II) vs menos estrictas (IV+VI).
# --- EXPERIMENTA AQUÍ ---
# Pregunta 1: tamaño de las PAs por década
import pandas as pd
decadas_data = pas.copy()
decadas_data = decadas_data[decadas_data['YEAR_DESIG'] > 0]
decadas_data['decada'] = (decadas_data['YEAR_DESIG'] // 10 * 10).astype(int)
resumen_por_decada = decadas_data.groupby('decada').agg(
n_pas=('GIS_A_km2', 'count'),
area_media_km2=('GIS_A_km2', 'mean'),
area_mediana_km2=('GIS_A_km2', 'median'),
area_total_km2=('GIS_A_km2', 'sum'),
).round(0)
print('Resumen por década:')
print(resumen_por_decada)
print()
# Comparar 2010s vs el resto
pa_2010s = decadas_data[decadas_data['decada'] == 2010]['GIS_A_km2']
pa_resto = decadas_data[decadas_data['decada'] != 2010]['GIS_A_km2']
print(f'Mediana 2010s: {pa_2010s.median():,.0f} km²'.replace(',', '.'))
print(f'Mediana resto: {pa_resto.median():,.0f} km²'.replace(',', '.'))
print(f'¿Las nuevas son más pequeñas? {"Sí" if pa_2010s.median() < pa_resto.median() else "No"}')
Resumen por década:
n_pas area_media_km2 area_mediana_km2 area_total_km2
decada
1930 1 4300.0 4300.0 4300.0
1950 2 2778.0 2778.0 5556.0
1960 5 1403.0 814.0 7014.0
1970 8 3379.0 2437.0 27031.0
1980 2 193.0 193.0 385.0
1990 2 416.0 416.0 832.0
2000 11 809.0 503.0 8898.0
2010 39 770.0 243.0 30034.0
2020 1 1945.0 1945.0 1945.0
Mediana 2010s: 243 km²
Mediana resto: 615 km²
¿Las nuevas son más pequeñas? Sí
Créditos#
Notebook: Lab de Ciencia a Mordiscos · Reproducible bajo MIT License.
Repositorio: github.com/Ciencia-a-Mordiscos/lab · Issues y mejoras bienvenidos.
Datos originales:
Shapefile oficial de PAs de Etiopía (Sep 2024) — GitHub SCJago/protected_area_performance — supplementary del paper, CC BY 4.0
Resultados ATT y estadísticos — extraídos del texto del paper (Open Access, CC BY 4.0)
Fuentes#
Paper: Trade-offs between nature and people in Ethiopia’s protected areas
Nature Ecology & Evolution, 2026-05-12
Supplementary Material: Supplementary Information (PDF)
Dataset canónico: Shapefile oficial de áreas protegidas de Etiopía (Sep 2024)
GitHub SCJago/protected_area_performance · supporting data del paper, CC BY 4.0
23 afirmaciones verificadas contra estas fuentes